<binding.atom> Introduction
The Tuscany Java SCA runtime supports Atom using the <binding.atom> extension. Tuscany can communicate with services that provide or consume items described in the Atom Syndication Format and Atom Publishing Protocol. The Atom protcol is an additional conceptual layer that operates on top of the Hyper Text Transfer Protocol, so it is useful to understand that underlying protocol as well. Reference materials on these specifications is available here.
![]() Some of the function described here is included in the Tuscany 1.3.2 and 1.4 releases. The complete timeline of available and future plans is given in the Tuscany Web 2.0 Roadmap.
Some of the function described here is included in the Tuscany 1.3.2 and 1.4 releases. The complete timeline of available and future plans is given in the Tuscany Web 2.0 Roadmap.
Using the Tuscany Atom binding
The primary use of the Atom binding is to provide support for collections that can be shared in a distributed fashion. Examples of shared collections includes shopping carts, telephone directories, insurance forms, and blog sites. These collections of items can be added, retrieved, updated, and deleted using the 4 basic actions of the HTTP protocol:
- POST (create or add)
- GET (retreive or query)
- PUT (update)
- DELETE (destroy or remove
The simplest way to use the Atom binding is to declare a collection as a service and provide an HTTP address where one can access the service. This service is declared in an SCA composite file which describes the SCA domain.
<service name="customer" promote="CustomerCollection"> <tuscany:binding.atom uri = "http://localhost:8084/customer"/> </service>
The service can be implemented in Java or any of the the Tuscany implementation types. For example, here is a way to create an implmentation for the above CustomerCollection service in the Java type.
<component name="CustomerCollection">
<implementation.java class="org.apache.tuscany.sca.binding.atom.CustomerCollectionImpl"/>
</component>
A collection that uses the Atom binding usually implements the Collection interface given in the package org.apache.tuscany.sca.binding.atom.collection. This interface declares the basic access methods mentioned above (post, get, put, and delete), and the data types on the methods are expressed as Atom type objects Feed and Entry. In other words, one can view the collection as an Atom Feed, and manipulate items in the Feed as Atom Entries. This shows the basic methods of the Atom Collection intergface in Tuscany:
public interface Collection { Entry post(Entry entry); Entry get(String id) throws NotFoundException; void put(String id, Entry entry) throws NotFoundException; void delete(String id) throws NotFoundException; Feed getFeed(); Feed query(String queryString); }
It is up to the developer or implementer of the shopping cart, telephone directory, or blog site to provide the code that implements the Collection interface. The developer or implementor also provides the code that translates from the business objects (shopping cart items, directory entries, insurance forms, blog articles) to the Atom model objects Feed and Entry.
One of the features of using this binding is that your business objects (shopping cart items, directory entries, insurance forms, and blog articles) can now be easily published and shared by the many Atom supporting tools such as feed readers, web browsers, and syndication aggregation. In other words, people can access your collection most anywhere on any device.
Example
Continuing with the CustomerCollection example shown above, let's see how one of the common access methods. In this case, let's look at the post method and how one would add a new item to the collection. When you declared your Atom binding in your SCA composite, you also provided a uri for your collection. Using a web browser or other device, a user performs an HTTP put request to this uri, with the body of the put containing the data. Tuscany SCA performs the task of invoking the correct service and finding the Java implementation for your collection and calling the correct method.
public Entry post(Entry entry) {
// 1. Validate entry fields
if (entry.getTitle() != null ) {
entryID = "tag:" + site "," + todaysDate + ":" + title;
entry.setID( entryID );
}
// 2. Provide any additional data.
entry.setUpdated( new Date() );
// 3. Store data in local collection or data base.
entries.put(id, entry);
// 4. Return entry to poster.
return entry;
}
Much of the code consists of converting from a Feed or Entry to a business data model and storing to a collection.
Tuscany uses the Apache Abdera project to provide a model for Atom data. Please see Apache Abdera for the Java method to access Atom Feeds and Entries, and how to easily convert these Java objects to and from XML.
Other Features of the Tuscany Atom Binding
More advanced features of the Tuscany Atom binding are described below.
Data Caching using ETags, Last-Modified, and other Header Commands
Atom feeds and entries can often be very large pieces of data. Since Tuscany uses the Atom data binding as one of its supported bindings, there is the potential that many requests for data may have large pieces of data associated with a request.
Hyper Text Transfer Protocol (HTTP), the basis of the web, has support to help limit or cache the amount of data shared between a client and server by adding tags to a resource reques. These header tags are the ETag and the Last-Modified tags. When used with a predicate tag such as If-Match, If-Not-Match, If-Modified-Since, If-Unmodified-Since, etc., the client and the server can avoid shipping large pieces of data when updated data is not needed.
The following entry scenarios show how Tuscany supports this form of caching throught ETags, Last-Modified, and other Header Commands.
- Posting new entry data to a feed
(Show entry data post request, item does not exist on server, server response code 200, return entry data body) - Updating existing entry data in a feed
(Show data update put, If-Match precondition, item is newer and matching, matching return code 412) - Requesting existing entry data
(Show get via ETag, If-None-Match precondition, modified entry data item, matching entry body returned) - Requesting stale entry data
(Show get via ETAG, If-None-Match precondition, unmodified entry data item, not modified return code 304) - Requesting up-to-date entry data
(Show request via last-modified date, entry data is unmodified, Not modified return code 304) - Requesting out-of-date entry data
(Show request via last-modified date, entry data is modified, updated data is returned)
Tuscany provides a test case ProviderEntryEntityTagsTest.java in module binding.atom.abdera that validates these Entry caching scenarios via JTest. Additionally, the following Feed scenarios are provided in the test case ProviderFeedEntityTagsTest.java.
- Test feed basics
(Request Atom feed. Check that feed is non-null, has Id, title, and updated values. Check for Etag and Last-Modified headers) - Test Unmodified If-Match predicate
(Request feed based on existing ETag. Use If-Match predicate in request header. Expect status 200 and feed body.) - Test Unmodified If-None-Match predicate
(Request feed based on existing ETag. Use If-None-Match predicate in request header. Expect status 304, item not modified, no feed body.) - Test Unmodified If-Unmodified-Since predicate
(Request feed based on very current Last-Modified. Use If-Unmodified-Since predicate in request header. Expect status 304, item not modified, no feed body.) - Test Unmodified If-Modified-Since predicate
(Request feed based on very old Last-Modified. Use If-Modified-Since predicate in request header. Expect status 200, feed in body.) - Test Modified If-None-Match predicate
(Request feed based on existing ETag. Use If-None-Match predicate in request header. Expect status 200, feed in body.) - Test Modified If-Match predicate
(Request feed based on existing ETag. Use If-Match predicate in request header. Expect status 412, precondition failed, no feed in body.) - Test Modified If-UnModified-Since predicate
(Request feed based on very recent Last-Mod date. Use If-Unmodified-Since predicate in request header. Expect status 304, no feed in body.) - Test Modified If-Modified-Since predicate
(Request feed based on very old Last-Mod date. Use If-Modified-Since predicate in request header. Expect status 200, feed in body.)
Support of Web 2.0 data caching via ETags and Last-Modified fields allow the Tuscany user to save bandwidth and re-requests of data. Especially in the area of content feeds which can have very large data objects, the ability to cache improves server performance and reduces network bottlenecks. A full end-to-end demonstration of this network savings is being created via Jira TUSCANY-2537 which will show caching in the feed aggregator sample.
Support for Negotiated Content Types
Requests for data now respond with negotiated content types. In other words, the requester can now state which content types are preferred, and the responder can provide different content types. The data preference is expressed in the request header "Accept" parameter.
These data binding types are supported:
- Atom XML format (Request header Accept=application/atom+xml)
- Atom in JSON format (Request header Accept=application/atom+json)
The following content types are requestable in different data bindings
- Atom entry data (MIME type application/atom+xxx;type=entry where xxx=xml or json)
- Atom feed data (MIME type application/atom+xxx;type=feed where xxx=xml or json)
For example, the requester asks for an Atom entry with no Accept header or Accept header value is application/atom+xml. The returned response body contains:
<?xml version='1.0' encoding='UTF-8'?> <entry xmlns="http://www.w3.org/2005/Atom"> <title type="text">customer Fred Farkle</title> <updated>2008-08-08T18:40:30.484Z</updated> <author> <name>Apache Tuscany</name> </author> <content type="text">Fred Farkle</content> <id>urn:uuid:customer-91d349b3-4b8b-4cfa-b9e9-d999f9937085</id> <link href="urn:uuid:customer-91d349b3-4b8b-4cfa-b9e9-d999f9937085" rel="edit" /> <link href="urn:uuid:customer-91d349b3-4b8b-4cfa-b9e9-d999f9937085" rel="alternate" /> </entry>
In contrast, the requester asks for an Atom entry with Accept header value is application/atom+json. The returned response body contains:
{
"id":"urn:uuid:customer-91d349b3-4b8b-4cfa-b9e9-d999f9937085",
"title":"customer Fred Farkle",
"content":"Fred Farkle",
"updated":"2008-08-08T18:40:30.484Z",
"authors":[{
"name":"Apache Tuscany"
}
],
"links":[{
"href":"urn:uuid:customer-91d349b3-4b8b-4cfa-b9e9-d999f9937085",
"rel":"edit"
},{
"href":"urn:uuid:customer-91d349b3-4b8b-4cfa-b9e9-d999f9937085",
"rel":"alternate"
}
]
}
The ability to view entires and feeds in multiple data formats allows the Tuscany user extreme flexibility in parsing and processing data returned by a service or collection.
Service and Workspace Document Support (application/atomsvc+xml)
Prior to this implementation, there was a dummy service document provided when you visited an Atom feed service address with an "atomsvc" extension. For example, running the the Atom service binding unit tests, one could visit http://localhost:8080/customer/atomsvc and receive the following service document:
<?xml version='1.0' encoding='UTF-8'?> <service xmlns="http://www.w3.org/2007/app" xmlns:atom="http://www.w3.org/2005/Atom"> <workspace> <atom:title type="text">resource</atom:title> <collection href="http://luck.ibm.com:8084/customer"> <atom:title type="text">collection</atom:title> <accept>application/atom+xml;type=entry</accept> <categories /> </collection> </workspace> </service>
This dummy implementation did not provide a true collection name, URL to the collection, accept MIME types or categories.
Following the inclusion of TUSCANY-2597 and the new implentation, the Tuscany Atom binding will correctly populate an atomsvc document with information from the feed and give correct information for discovery. Now , running the the Atom service binding unit tests, one could visit http://localhost:8080/customer/atomsvc and receive the following service document:
<?xml version='1.0' encoding='UTF-8'?> <service xmlns="http://www.w3.org/2007/app" xmlns:atom="http://www.w3.org/2005/Atom"> <workspace xml:base="http://localhost:8084/"> <atom:title type="text">workspace</atom:title> <collection href="http://localhost:8084/customer"> <atom:title type="text">customers</atom:title> <accept>application/atom+xml; type=feed</accept> <accept>application/json; type=feed</accept> <accept>application/atom+xml; type=entry</accept> <accept>application/json; type=entry</accept> <categories /> </collection> </workspace> </service>
The service document is now properly populated with URLs, titles, accept MIME types and categories. These are elements that are needed for collection discovery and visitatin.
Support for full JavaScript Atom client.
After creating and publishing your SCA service, it can be tedious converting to and from Atom Feeds and Entries on the client side. Tuscany provides a full JavaScript object model for Atom Feeds, Entries, and other data objects. This benefits customers and client developers by providing an easy model to use in HTML, JSP, scripts, GUIs, and other client side technology.
For example, prior to this feature, developers would have to develop code in XML to manipulate nodes in the XML document that represented the current page:
var entries = feed.getElementsByTagName("entry"); var list = ""; for (var i=0; i<entries.length; i++) { var item = entries[i].getElementsByTagName("content")[0].firstChild.nodeValue; list += item + ' <br>'; }
Using the new JavaScript client object model, the code is greatly simplified and easier to understand:
var entries = feed.getEntries(); var list = ""; for (var i=0; i<entries.length; i++) { var item = entries[i].getContent(); list += item + ' <br>'; }
Additionally, the Tuscany Atom JavaScript client provides full deserialization and serialization to and from the JavaScript Atom model and its XML format. In other words let's say you create an HTML page that scrapes a data base and wants to submit the data as an entry to a collection of blog articles. You can create the Entry data using the JavaScript Entry model:
var entry = new Entry();
entry.setNamespace( "http://www.w3.org/2005/Atom" );
entry.setTitle( "Atom-Powered Robots Run Amok" );
entry.setId( "urn:uuid:1225c695-cfb8-4ebb-aaaa-80da344efa6a" );
entry.setUpdated( "2003-12-13T18:30:02Z" );
entry.setContent( "Some text." );
entry.addAuthor( new Person( "John Doe" ) );
entry.addAuthor( new Person( "Mark Pilgrim", "f8dy@example.com" ));
entry.addContributor( new Person( "Sam Ruby" ));
entry.addContributor( new Person( "Joe Gregorio" ));
entry.addLink( new Link( "http://example.org/edit/first-post.atom", "edit" ));
Now to convert this code to XML and submit it to a site is easy using the Tuscany Atom JavaScript client:
var text = entry.toXML();
The text string now contains the fully serialized XML format of the Entry object
"<?xml version="1.0"?>
<entry xmlns="http://www.w3.org/2005/Atom">
<title>Atom-Powered Robots Run Amok</title>
<id>urn:uuid:1225c695-cfb8-4ebb-aaaa-80da344efa6a</id>
<updated>2003-12-13T18:30:02Z</updated>
<author><name>John Doe</name></author>
<content>Some text.</content>
<link rel="edit" href="http://example.org/edit/first-post.atom"/>
</entry>"
Similarly the Tuscany Atom JavaScript client contains methods for deserializing from XML reperesentations to a JavaScript Atom model:
var feed = new Feed(); feed.readFromXML( xmlString );
A full example showing how to use this client model is given in implementation-widgets-runtime. The store.html page shows the older style of document XML manipulation. The storeJS.html page shows the newer style of JavaScript object manipulation.
Support for Posting and Putting Media Items
The Atom Publishing Protocol provides for a separate space for storage of media resources. The purpose of a separate space for these resources is to keep feeds and entries from growing too large with the contents of typically large items. Media resources can be any binary object that is supported by a MIME type, but typically media resources include video, image, and audio type files.
Media resources are maintained by the collection implementor, and are given a dual identity. There is a location in the media respository, typically where one places the media files, and there is a location in the feed or entry space. This second reference is known as a media link entry.
The Tuscany package at org.apache.tuscany.sca.binding.atom.collection (in tuscany-binding-atom-abdera package) has the following interface for MediaCollection:
/**
* Creates a new media entry
*
* @param title
* @param slug
* @param contentType
* @param media
*/
Entry postMedia(String title, String slug, String contentType, InputStream media);
/**
* Update a media entry.
*
* @param id
* @param contentType
* @param media
* @return
*/
void putMedia(String id, String contentType, InputStream media) throws NotFoundException;
These two methods are used to create (post) new media files, and update (put) new media information and edits. The media resources may be retrieved (get) or removed (delete) via the normal HTTP get and delete operations and the links returned by the post and get methods.
For instance, when creating a media resource, one typically posts the following information via an HTTP post request:
POST /edit/ HTTP/1.1 Host: media.example.org Content-Type: image/png Slug: The Beach Authorization: Basic ZGFmZnk6c2VjZXJldA== Content-Length: nnn ...binary data...
In turn, the Tuscany invocation framework invokes the postMedia shown above on the media collection implementation. The media collection implementation may then take the binary data from the media InputStream and store it to a media repository. The media collection implemenation should construct a proper Entry item via XML construction or some Atom model framework such as Apache Abdera. The Entry should contain the required elements (title, id, updated, summary, content, edit link, edit-media link) in order to provide the proper Atom Pub Protocol return headers and Entry data as given here:
HTTP/1.1 201 Created Content-Length: nnn Content-Type: application/atom+xml;type=entry;charset="utf-8" Location: http://example.org/media/edit/the_beach.atom <?xml version="1.0"?> <entry xmlns="http://www.w3.org/2005/Atom"> <title>The Beach</title> <id>urn:uuid:1225c695-cfb8-4ebb-aaaa-80da344efa6a</id> <updated>2005-10-07T17:17:08Z</updated> <author><name>Daffy</name></author> <summary type="text" /> <content type="image/png" src="http://media.example.org/the_beach.png"/> <link rel="edit-media" href="http://media.example.org/edit/the_beach.png" /> <link rel="edit" href="http://example.org/media/edit/the_beach.atom" /> </entry>
Note that the edit link provides the Atom Feed link to the media entry, and the edit-media link provides the media repository link to the media entry. Use these links to get and delete media.
A special convention has been implemented to allow the media collection implementation to return properties in the response header. The summary element of the Entry returned may contain a set of key=value properties separated via commas. For example, in order to provide return Content-Type and Content-Length values in the response header, one can created this text in the postMedia Entry summary element: Content-Type=image/jpg,Content-Length=21642.
The putMedia method acts in much the same way, but the URI to the item should contain an ID to the media being updated. For instance, if the usual post and get feed URI is http://localhost:8084/receipt, then to update the media given above one would put to the URI http://localhost:8084/receipt/urn:uuid:1225c695-cfb8-4ebb-aaaa-80da344efa6a. Here is an example of a put request:
PUT /edit/urn:uuid:1225c695-cfb8-4ebb-aaaa-80da344efa6a HTTP/1.1 Host: media.example.org Content-Type: image/png Authorization: Basic ZGFmZnk6c2VjZXJldA== Content-Length: nnn ...binary data...
After the above put request, the Atom binding will invoke the media collection implementation putMedia method. The media collection should update the media if the ID exists (and a 200 OK status code will return), or the media collection should throw a NotFoundException if the ID does not exist (and a 404 not found status code will return).
The above scenarios are documents in the MediaCollectionTestCase unit test case in the binding-atom-abdera module in the Tuscany code base.
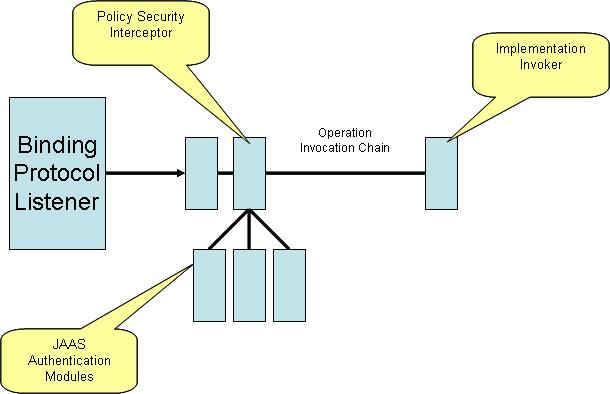
Security Policy support in HTTP and Web 2.0 Bindings
| work in progress |
Scenarios
- A Web 2.0 application requires that a user get authenticated before it can access the application.
- A Web 2.0 application requires that all communication between client/server be done using SSL.
- A given service, exposed using a web 2.0 binding requires user authentication.
- A given operation, exposed using a web 2.0 binding requires user authentication.
Policy Interceptor
The design approach that is being considered is to inject policy security interceptors, that would properly validate and enforce the security intents.
The authentication will be done using JAAS modules for authentication, and initially we would support authenticating to a list of username/password supplied by the application or using an LDAP.